
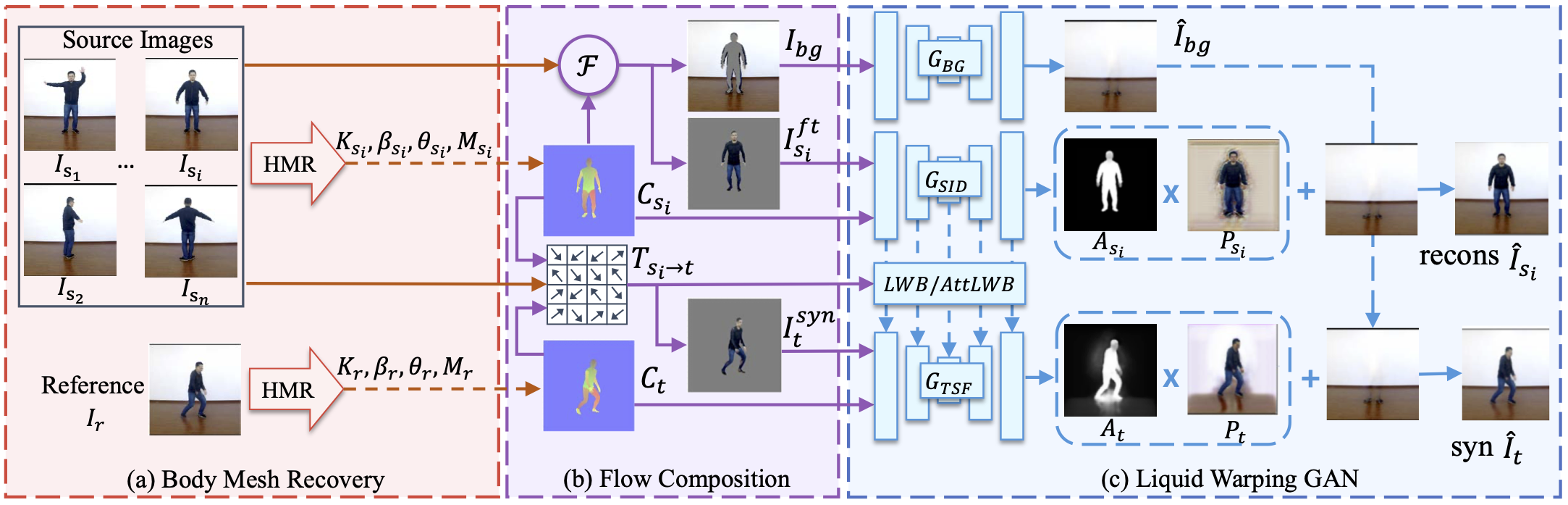
The training pipeline of our method. We randomly sample a pair of images from a video, denoting the source and the reference image as \(I_{s_i}\) and \(I_r\). (a) A body mesh recovery module will estimate the 3D mesh of each image and render their correspondence map, \(C_s\) and \(C_t\); (b) The flow composition module will first calculate the transformation flow \(T\) based on two correspondence maps and their projected vertices in the image space. Then it will separate the source image \(I_{s_i}\) into a foreground image \(I^{ft}_{s_i}\) and a masked background \(I_{bg}\). Finally it warps the source image based on the transformation flow \(T\) and produces a warped image \(I_{syn}\); (c) In the last GAN module, the generator consists of three streams, which separately generates the background image \(\hat{I}_{bg}\) by \(G_{BG}\), reconstructs the source image \(\hat{I}_s\) by \(G_{SID}\) and synthesizes the target image \(\hat{I}_t\) under the reference condition by \(G_{TSF}\). To preserve the details of the source image, we propose a novel LWB and AttLWB which propagates the source features of \(G_{SID}\) into \(G_{TSF}\) at several layers and preserve the source information, in terms of texture, style and color.
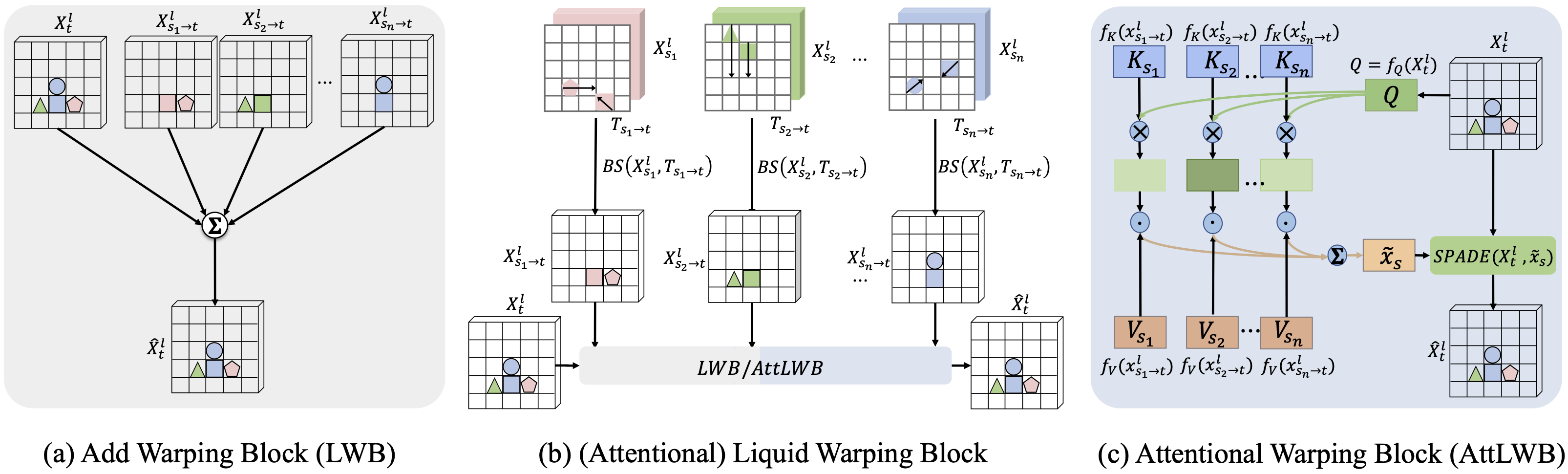
Illustration of our LWB and AttLWB. They have the same structure illustrated in (b) but with separate AddWB (illustrated in (a)) or AttWB (illustrated in (b)). (a) is the structure of AddWB. Through AddWB, \(\widehat{X}_t^{l}\) is obtained by aggregation of warped source features and features from \(G_{TSF}\). (b) is the shared structure of (Attentional) Liquid Warping Block. \(\{X^{l}_{s_1}, X^{l}_{s_2}, ..., X^{l}_{s_n}\}\) are the feature maps of different sources extracted by \(G_{SID}\) at the \(l^{th}\) layer. \(\{T_{s_1\to t}, T_{s_2\to t},...,T_{s_n\to t}\}\) are the transformation flows from different sources to the target. \(X^{l}_t\) is the feature map of \(G_{TSF}\) at the \(l^{th}\) layer. (c) is the architecture of AttWB. Through AttWB, final output features \(\widehat{X}_t^{l}\) is obtained with SPADE by denormalizing feature map from \(G_{TSF}\) with weighted combination of warped source features by a bilinear sampler (BS) with respect to corresponding flow \(T_{s_i\to t}\).
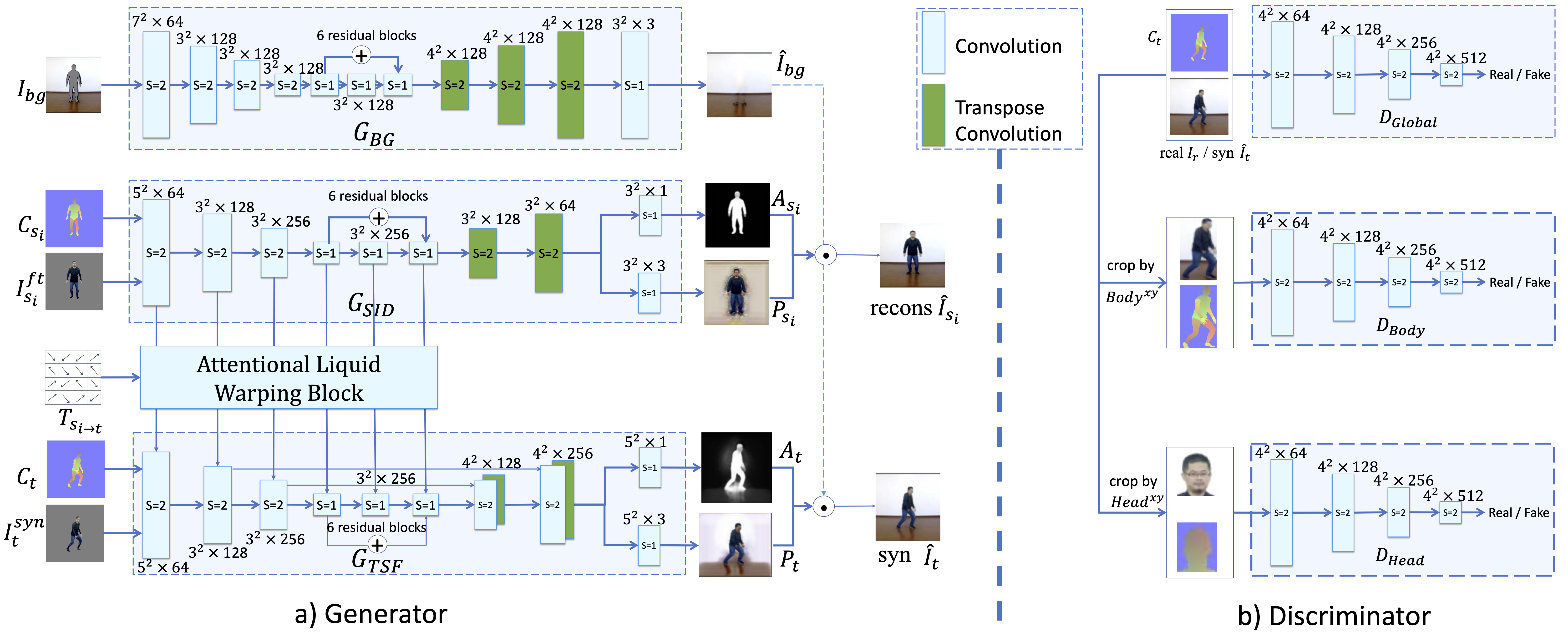
The details of network architectures of our Attentional Liquid Warping GAN, including the generator and the discriminator. Here \(s\) represents the stride size in convolution and transposed convolution.
@misc{liu2020liquid,
title={Liquid Warping GAN with Attention: A Unified Framework for Human Image Synthesis},
author={Wen Liu and Zhixin Piao, Zhi Tu, Wenhan Luo, Lin Ma and Shenghua Gao},
year={2020},
eprint={2011.09055},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@InProceedings{lwb2019,
title={Liquid Warping GAN: A Unified Framework for Human Motion Imitation, Appearance Transfer and Novel View Synthesis},
author={Wen Liu and Zhixin Piao, Min Jie, Wenhan Luo, Lin Ma and Shenghua Gao},
booktitle={The IEEE International Conference on Computer Vision (ICCV)},
year={2019}
}